
Basics of machine learning and supervised learning

Objectives: Gain basic knowledge of neural networks.
Introduction to Machine Learning (ML)
Machine learning (ML) is part of artificial intelligence (AI) that uses algorithms and statistical models to make computers learn and enhance their performance on a specific task without being specifically programmed. Specifically, machine learning allows computers to automatically improve their performance on a task by analyzing and learning from data rather than relying on explicitly programmed rules.
There are many types of machine learning, including supervised, unsupervised, and reinforcement learning.
In this lesson, we will focus on supervised learning, a kind of machine learning in which the algorithm is trained using a dataset with labels, where the correct output for each example in the training set is provided.
Our goal of supervised learning is to build a model that can make predictions about new, unseen examples based on the patterns it has learned from the training data.
Supervised Learning in Bioinformatics
Bioinformatics is the science field that involves using computational techniques to analyze and interpret biological data. Machine learning is crucial in bioinformatics, as it can analyze and interpret extensive and complex datasets generated by modern genomic technologies.
One example of supervised learning in bioinformatics is protein function prediction. Proteins are complex molecules that perform a wide range of functions in living organisms, and predicting the function of a protein based on its sequence is challenging.
We can train machine learning algorithms on labeled datasets of protein sequences and their known functions and then use them to predict the function of novel proteins based on their sequence.
Another example of the use of supervised learning in bioinformatics is in the prediction of disease risk. We can train machine learning algorithms using labeled datasets of genetic variants and their associated disease risks and then use them to predict the risk of a particular disease for an individual based on their genetic profile.
Overall, supervised learning has a wide range of applications in bioinformatics and has the potential to significantly improve our understanding of biological processes and improve the diagnosis and treatment of diseases.
Steps in a Supervised Learning Task
- 1. Collect and preprocess the data:
- The first step in any machine learning task is collecting and preprocessing data. In preprocessing step, we clean and format the data and select a subset of the data to use for training and testing.
- 2. Split the data into a training set, a test set, and a validation set:
- Once the data has been preprocessed, it is typically split into a training, validation, and test set. We use a training set containing the labeled data to train our machine learning model, the test we use to evaluate the model's performance. Finally, we use the test set to test the model's final performance on data that the model has not seen during the training.
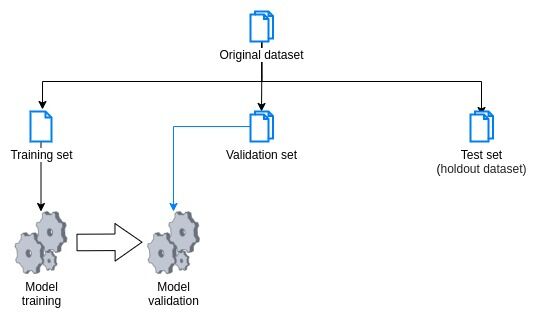
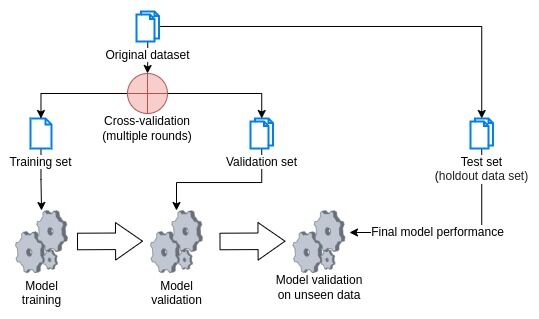
- 3. Choose an appropriate machine learning model and training algorithm:
- There are many different machine learning models and training algorithms to choose from, and the right choice will depend on the specific task and the characteristics of the data. Some standard models include linear regression, logistic regression, and support vector machines.
- 4. Train the model on the training data:
- Once we have chosen a model and training algorithm, we train the model on the training dataset. We also adjust the model's parameters to minimize the prediction error on the training data.
- 5. Evaluate the model on the test and validation datasets:
- After we have trained the model, we evaluate it on the test data to see how well it performs on unseen examples. This validation will typically involve calculating a performance metric, such as accuracy or F1 score, on the test data.
- 6. Fine-tune the model:
- Based on the evaluation results, we may need to fine-tune it to improve its performance. Fine-tuning could involve further adjusting the model's parameters and choosing a different model or training algorithm.
Proceed to the next lecture: Neural network architecture and activation functions