
Introduction to neural networks and their applications in bioinformatics
Objectives: Gain basic knowledge of neural networks.
Neural networks are machine learning algorithms consisting of multiple layers of interconnected nodes that process and transmit information using weighted connections. Neural networks are beneficial for tasks that require learning and adapting based on data, such as pattern recognition, classification, and prediction.
In bioinformatics, neural networks are applied to a wide range of problems, including the prediction of protein structures, the analysis of gene expression data, and the identification of disease-associated genetic variants.
Basics of Neural Networks
Neural networks comprise multiple layers of interconnected nodes, also known as neurons (Figure 1).
Each neuron receives input from other neurons from the previous layer and processes this input using a nonlinear activation function.
The output of a neuron is transmitted to other neurons in the next layer via weighted connections, which are adjusted during the learning process to optimize the neural network's performance.
The layers of a neural network are organized into an input layer, hidden layers, and an output layer.
The input layer takes the raw input data that are subsequently processed by the hidden layers and produces the output at the output layer.
The hidden layers are responsible for extracting features and patterns from the input data and passing them on to the output layer.
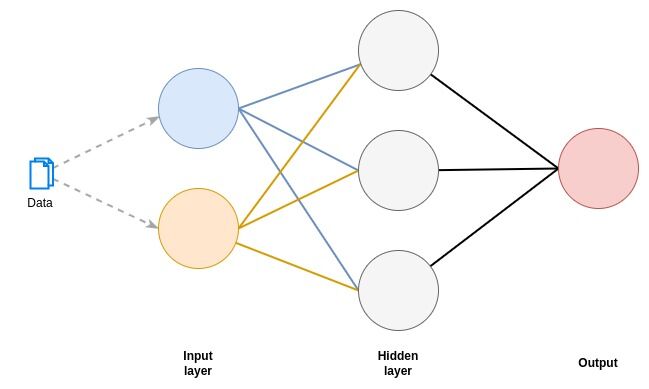
Figure 1. An illustration of a simple neural network consisting of nodes and corresponding edges representing the connections between the nodes.
Types of Neural Networks
Several types of neural networks exist, including feedforward networks, convolutional neural networks (CNNs), recurrent neural networks (RNNs), and long short-term memory (LSTM) networks.
Feedforward networks are the most basic type of neural network, in which the flow of information is unidirectional from the input layer to the output layer
Convolutional neural networks, CNNs, are specialized neural networks designed for image-processing tasks. They consist of multiple layers of convolutional and pooling layers, which extract features from the input image and reduce its dimensionality.
Recurrent neural networks, RNNs, are neural networks designed to process sequential data, for example, time series or natural language text. They use feedback connections to store information from previous time steps and incorporate it into the processing of the current time step.
Long short-term memory, LSTM, networks are a type of RNN that are particularly effective at dealing with long-term dependencies in sequential data. They use a particular type of neuron called an LSTM cell, which can store information for long periods and selectively expose it to the rest of the network.
Training Neural Networks
Neural networks are trained using a process called backpropagation. The backpropagation algorithms adjust the weights of the connections between neurons based on the error between the predicted output and the true output.
The training process begins with presenting a set of input-output pairs, called the training set, to the neural network.
The neural network processes the input and produces an output, then compares it to the true output to calculate the error.
The error is then propagated back through the network and used to adjust the weights of the connections to reduce the error on the next iteration.
This process is repeated until the error is minimized, at which point the neural network is considered to be trained.
Applications of Neural Networks in Bioinformatics
Neural networks are applied to many problems in bioinformatics, including predicting protein structures, analyzing gene expression data, and identifying disease-associated genetic variants. For example, neural networks are used to predict the three-dimensional structure of proteins based on their amino acid sequence.
Predicting three-dimensional protein structures is challenging, as proteins can adopt a wide range of structural conformations, and their structure is essential for their function. Neural networks are particularly effective at this task, outperforming traditional methods such as homology modeling and ab initio prediction.
Neural networks have also been applied to the analysis of gene expression data, which reflects the activity of genes in different biological samples. This data can be used to identify differentially expressed genes in varied conditions or diseases and to understand the underlying molecular mechanisms. Neural networks have been shown to be effective at detecting patterns and correlations in gene expression data and identifying genes associated with specific diseases or traits.
In addition, neural networks have been used to identify disease-associated genetic variants, which are changes in the DNA sequence associated with an increased risk of a particular disease. Identifying associations is a significant problem, as determining these variants can provide insight into the underlying causes of diseases and inform the development of therapeutic interventions. Neural networks identify disease-associated variants effectively, particularly when combined with other machine-learning techniques such as support vector machines or random forests.
Neural networks are a powerful tool for solving a wide range of problems in bioinformatics and have the potential to advance our understanding of biological systems and the development of new therapies.
Proceed to the next lecture: Basics of machine learning and supervised learning